4 Procesiranje naravnih jezikov, modeliranje tem in literatura
Naravni jeziki so tisti jeziki, ki jih ljudje vsakodnevno uporabljamo in z njimi komuniciramo, pri tem pa se ti jeziki nenehno spreminjajo. Umetni jeziki so po drugi strani namenjeni za specifične naloge in so nespremenljivi, to so na primer programski jeziki. Obdelava naravnih jezikov (ang. Natural Language Processing ali s kratico NLP) se ukvarja z računalniško obdelavo “človeških” jezikov in pomeni most med naravnimi in računalniškimi jeziki.
Procesiranje naravnih jezikov uporablja modele strojnega učenja za analizo, interpretacijo ali ustvarjanje naravnih jezikov. Obdelava naravnih jezikov je uporabna za številne vsakodnevne naloge, na primer za prepoznavanje govora in avtomatsko prevajanje besedil.
1 Iskanje tematik znotraj literarnega korpusa
Raziskave na področju procesiranja naravnih jezikov so namenjene oblikovanju algoritmov in orodij za avtomatsko obdelavo jezika, osredotočajo se na izboljšave meril znotraj svojih procesov ter razvoj optimalnih algoritmov. S preizkušanjem njihove učinkovitosti na podlagi standardnih korpusov besedil je možno na sistematičen način primerjati različne pristope. Raziskave znotraj digitalne humanistike se po drugi strani ne osredotočajo v tolikšni meri na same algoritme, ampak bolj na rezultate, na podlagi katerih raziskovalke in raziskovalci odgovarjajo na svoja raziskovalna vprašanja. Zaradi tega razloga se vsaka posamezna študija osredotoča na ožji nabor podatkov, ki je pogosto edinstven.[1] Pred izdelavo tematskih modelov je običajno, da korpus uredimo, in sicer je ključno, da izločimo t. i. prazne besede (ang. stop words):[2] nepolnopomenske besede, imena mesecev, dni v tednu, literarnih junakov ipd.[3]
Primer: korpus ELTeC-slv
 2 Modeliranje tem v književnih besedilih
2 Modeliranje tem v književnih besedilih
Ko procesiranje naravnih jezikov uporabimo na korpusih književnih del, lahko dobimo na primer pregled nad temi besedili s samodejnim izločanjem osrednjih tematik danega besedila in odnosov med njimi.
Pri analizi besedil gre za samodejno iskanje besed in besednih zvez, ki povzemajo vsebino dela ali korpusa književnih del, s tem pa lahko raziskovalke in raziskovalci izluščijo ključne tematske poudarke tekstov. Gre za preverjanje, kako pogosto se določene besede ali besedne zveze pojavljajo v danem književnem besedilu ali celotnem literarnem korpusu, s tem pa je mogoče ugotoviti, katere teme in motivi v delih prevladujejo ter kako se medsebojno povezujejo.
Z modeliranjem tem tako ugotovimo, katere teme so v določenem literarnem besedilu ali skupini besedil ključne in kateri so njihovi osrednji vsebinski poudarki. Poleg tega lahko na ta način na primer ugotavljamo, katere teme so bile najbolj zanimive za literate in literatke v določenem zgodovinskem obdobju. Tematski modeli so uporabni za različne namene v literarnovednih raziskavah: za združevanje dokumentov v skupine, organiziranje velikih korpusov besedilnih podatkov in pridobivanje informacij iz besedil.[5]
Primer: vizualizacije literarne produkcije ameriških Ircev
Primer: tematike, povezane z industrializacijo, meščanstvom, političnim udejstvovanjem in nacionalnimi idejami v slovenski literaturi 19. stoletja
Lucija Mandić[7] je izvedla modeliranje tem na slovenskem korpusu ELTeC-slv, cilj raziskave pa je bil ugotoviti, katere teme so povezane z industrializacijo, meščanstvom, političnim udejstvovanjem in nacionalnimi idejami v daljši slovenski pripovedni prozi 19. stoletja. Študija izlušči naslednje teme v besedilnem korpusu, ki jih lahko povežemo z omenjenimi tematikami:
- politika: volitev, komisar, glavar, kandidat, shod, stranka, narod, volilec, poslanec, večer;
- nacionalna ideja: narod, država, stoletje, jezik, pesnik, zgodovina, korist, nega, rod, duh;
- industrializacija: zdravnik, gospod, seme, nadzornik, delavec, ravnatelj, tovarna, vrata, delo, glava;
- plemstvo: baron, grofica, gospod, dan, misel, beseda, družba, čas, srce, gospa;
- podeželje: pot, deklica, glava, večer, beseda, vas, mladenič, oče, mlin, raz;
- družina: mati, oče, dan, otrok, leto, sin, pismo, hiša, denar, mož;
- sentimentalnost: oči, glava, pogled, obraz, ljubezen, gospod, duša, ženska, lice, miza;
- meščanstvo: gospod, beseda, doktor, duh, društvo, prijatelj, sluga, gospa, oči, odvetnik.
Kot je razvidno s spodnje slike, se v korpusu največkrat pojavljata meščanska in kmečka tema, sledi jima ženska tema.
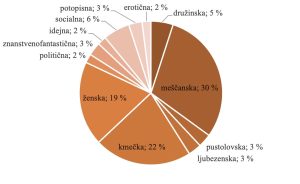
Slika: Sestava Korpusa glede na tematiko; vir: Mandić 2023
Mandić med drugim ugotavlja, da so teme “politika”, “nacionalna ideja”, “meščanstvo” in “sentimentalnost” v večji meri prisotne v delih z oznako roman kot v delih z oznako povest ali novela.[8]
3 Modeliranje tem in čustvene vsebine literarnih del
Čustva igrajo ključno vlogo pri razumevanju in analizi književnih besedil, raziskujemo pa jih lahko tudi z modeliranjem tem v literarnih korpusih. Slednje se povezuje z zaznavanjem čustvenih vidikov besedil prek čustvenih izrazov, s čimer dosežemo bolj celostno razumevanje vsebine, njene izrazne moči in vpliva na bralce. Gre na primer za raziskovanje, ali je besedilo pozitivno, negativno ali nevtralno naravnano in katera čustva v tekstu prevladujejo. Poleg tega je mogoče ugotavljati, kako so v besedilih čustveno obarvane določene tematike. Tovrstno modeliranje tem seveda ni rezervirano le za književnost: uporablja se za analize obsežnih objav na družabnih omrežjih, v časopisih, revijah, spletnih blogih ipd. Obsežna analiza tem v slovenskih medijih je na primer pokazala, da ima večina tem s politično tematiko negativen ali nevtralen sentiment, medtem ko je pozitivnih zelo malo.
Primer: Čustva v zbirki o Harryju Potterju
Zanimiva raziskava je merila in vizualizirala čustveno intenzivnost v šestih knjigah zbirke o Harry Potterju: Kamen modrosti, Dvorana skrivnosti, Jetnik iz Azkabana, Ognjeni kelih, Feniksov red in Princ mešane krvi. Kot je razvidno iz rezultatov raziskave, se čustveni naboj tekom zbirke stopnjuje, najbolj emocionalno intenziven pa je del z naslovom Princ mešane krvi. Trije najbolj čustveni trenutki v popularni zgodbi o čarovniku so sodeč po analizi tekom vseh obravnavanih nadaljevanj zbirke naslednji: kadar Harryja Potterja izbere Ognjeni kelih, kadar umre lik Cedric Diggory in kadar umre lik Dumbledore.[9]
3 Nekaj kritičnih pogledov na procesiranje naravnih jezikov in literaturo
Naravno procesiranje jezikov se srečuje z metodološkimi in tehničnimi izzivi, povezanimi med drugim z zgodovinskimi oblikami jezikov ter z večjezičnostjo, pa tudi s potrebami po bolj razvitih metodah digitalizacije besedil in polavtomatskim označevanjem tekstov.[10]
Ker je pri tej metodologiji, ki se intenzivno razvija, poudarek na razvoju novih računalniških sistemov ali izboljšanju obstoječih, je zelo pomembno, da se ti ovrednotijo na standardnih zbirkah podatkov z uporabo ponovljivih metod. Vendar to pomeni, da se raziskovalke in raziskovalci osredotočajo na omejene nabore podatkov zgolj v izbranih jezikih, zato se razvijajo orodja, ki so optimizirana izključnom za te ožje nabore podatkov ter izbrane jezike, pri tem pa izključujejo vse druge jezike, ki so s tega vidika manj razviti.[11] Orodja za naravno procesiranje jezikov so za širši krog uporabnikov precej zahtevna, da jih usvojimo, potrebujemo veliko časa. Med manj zahtevnimi orodji so po drugi strani na voljo predvsem orodja, ki so hkrati precej manj natančna, kakršno je Ngram Viewer na platformi Google Books.[12]
