2 Analysing ESL learners’ complexity development: linguistic corpus insights on L2 chunks acquired in online multimedia learning contexts.
Azzam Alobaid
Jawaharlal Nehru University, Centre for Linguistics, New Delhi, India
azzam.obaid85@gmail.com
This study investigates the relationship between the acquisition of L2 chunks and the development of L2 complexity among ESL learners. Previous research has shown that chunk learning is important for developing lexical and grammatical complexity in L2 speech and writing, particularly for bilingual learners. The study aims to achieve three objectives 1) to build a linguistic corpus of previously collected data from Arabic-speaking ESL learners who were frequently exposed to one ICT multimedia learning tool (i.e., YouTube captioned videos). This exposure potentially allowed the learners to accumulate a substantial amount of L2 chunks during their five-month ESL learning process, which consequently resulted in improved fluency and accuracy in their L2 writing and speech performance; 2) to examine these learners’ L2 development of lexical and grammatical complexity in their L2 speech and writing from the perspective of the frequency and range of the acquired L2 chunks, depending on the linguistic corpus-driven insights; and 3) to explore the correlation between frequency and range of acquired L2 chunks by learners and their lexical and syntactic complexity development. Our methodology for data analysis involves computer-based empirical analyses (both quantitative and qualitative) of language use by employing collections of spoken and written texts in exchange for lab-based communicative tasks. Results indicate that the frequency and range of learners’ acquired L2 chunks increased notably after five months of exposure to YouTube captioned videos. Moreover, there was a weak-to-moderate, positive correlation between the frequency and range of L2 chunks and the development of L2 complexity, particularly in relation to L2 speech complexity. These findings suggest that the more learners acquire L2 chunks, the more complex their L2 lexical and grammatical skills become.
- Motivation of Study
The acquisition of second language (L2) vocabulary is crucial for learners to achieve fluency and accuracy in their L2 writing and speaking (Saito & Hanzawa, 2018). The development of L2 vocabulary involves the acquisition of lexical items, such as words and phrases, as well as the ability to use these items in context (Nassaji, 2003). One approach to studying L2 vocabulary acquisition is to focus on the role of L2 chunks, which are words that always go together, such as fixed collocations, or that commonly do, such as certain grammatical structures that follow rules (Wray, 2008). Common examples of language chunks involve lexical phrases (i.e., sequences of words that collocate, often idiomatic, have a high-frequency of occurrence), set phrases (i.e., unvarying phrases having a specific meaning, such as ‘raining cats and dogs’, or being the only context in which a word appears, such as ‘amends’ in ‘make amends’), fixed phrases/ expressions (i.e., groups of words used together to express a particular idea or concept that is more specific than the individual words), collocations (i.e., predictable combination of words as in ‘heavy rain’, ‘do exercise’ – these can be made up of any kinds of words such as verbs, nouns, adverbs and adjectives), formulaic utterances (i.e., idioms, proverbs, pause fillers, counting, swearing, and other conventional and multiword units), sentence starters (i.e., words or phrases that introduce the rest of the sentence as in ‘due to’ ‘that’s why’ ‘this means that’), verb patterns (i.e., referring to what follows a verb – for example, some verbs can stand alone, (she smiled) while others have to be followed by an object (he smashed it)). (Lewis et al., 1997; McCarthy & Carter, 2004; Conklin & Schmitt, 2008).
Previous studies have suggested that exposure to multimedia learning tools, such as YouTube captioned videos, can help learners in the acquisition of L2 chunks which may in turn lead to the development of their L2 lexical and grammatical complexity (Alobaid, 2020, 2022a). Winke et al. (2010) reported that the use of captions induces deeper processing as they help learners to be more attentive to tasks, reinforce their acquisition of vocabulary through multiple modalities, and help them to figure out meaning through the unpacking of language chunks. From a cognitive perspective, Vanderplank (1988, 1990, as cited in Yang, 2020) found that the employment of non-typical input modes (i.e., video captioning) can facilitate processing language in chunks; this can be beneficial to overall L2 learning because the processing demands are reduced. Consequently, owing to the captioning effect which helps in chunk learning, “students can analyze and break down the aural input into meaningful constituent structures” (Winke et al., 2013).
More specifically, in studies that investigated the role and impact of multimedia learning tools, such as YouTube captioned videos, it was reported that some improvement was observed in the learners’ L2 lexical and grammatical complexity in writing and speaking of English as the target learning language for Arabic-speaking ESL learners (Alobaid, 2020, 2022a). This development was attributed, based on correlational analyses, to learners’ development or acquisition of new L2 chunks post their frequent exposure to one ICT multimedia learning tool, namely YouTube captioned videos and thus potentially acquired a large number of L2 chunks during their ESL learning process. However, the previous studies (ibid) did not report the frequency and range[1] of these L2 chunks in details. Given the power of corpus linguistic analysis and tools (Hunston, 2010; Poole, 2018), the current study seeks to examine these learners’ L2 chunks by employing a corpus that we build for this study using the data collected from previous studies (ibid). Upon building the corpus, we explore the nature of learners’ L2 chunks in terms of the frequency and range by using two of the most commonly corpus managers and text analysis software, namely AntConc and Sketch Engine.
This research attempts to address and find answers to the following research questions.
RQ1. What are the frequency and range of the acquired L2 chunks by learners who post their exposure to YouTube-captioned videos as an ICT multimedia learning tool?
RQ2. What is the correlation between the frequency and range of the acquired L2 chunks and learners’ lexical and syntactic complexity development?
Operationalising and Measurements of Lexical and Syntactic Complexity
Bulté and Housen (2012) proposed that lexical complexity is manifested at the observational level in L2 performance in terms of density, diversity and sophistication of L2 lexical items and collocations. In this work, the Type/ Token Ratio (TTR) metric is used for the measurement of the lexical complexity development for both L2 writing and speaking. Syntactic (or grammatical) complexity is proposed to be manifested as sentential complexity, clausal complexity and phrasal complexity (Norris & Ortega, 2009). The Number of Analysis of Speech Unit (AS-Units)[2] metric is used for the measurement of the syntactic complexity development of speech. However, the Number of T-units[3] metric is used for the measurement of the syntactic complexity development of writing.
Definition and Types of Chunks Used in the Analysis of this Study
Language chunks are broadly divided into two types, lexical and grammatical. In this study, language chunks are defined as a semi-fixed lexico-grammatical frame that carried a specific grammatical function (Ellis, 2003). The tracked chunks which were used in the analysis of this study are units of grammatical nature but expressed lexically such as auxiliary verbs, negations, prepositions, conjunctions, adverbs as action and quality intensifiers, etc. (Makarova & Polyakov, 2018), besides linguistic units (referred to as “productive speech formula” or “slot-and frame patterns” (Nattinger & DeCarrico, 1992) which include one or more open slots in which learners can place a variety of words such as ‘I can + verb’, ‘It + verb + that-clause’ (Taguchi, 2008). For examples of acquired chunks, see Table 9 and Figures 1 and 2 below.
- Methods and Materials
This is a corpus-based study that typically used corpus data in order to explore and validate the hypothesis that the greater number and range of L2 chunks that learners can accumulate over time can potentially contribute to the development of their L2 lexical and grammatical complexity (Pawley & Syder, 2000; Taguchi, 2008). The definition of corpus linguistics as a method underpins our approach to study.
To answer the first research question in this study, we explore the nature of learners’ L2 chunks in terms of frequency and range by using two of the most common corpus managers and text analysis software, namely AntConc and Sketch Engine. To answer the second research question, we employ Spearman’s correlation to help explain if there is any established correlation between the frequency and range of the acquired L2 chunks (as the independent variable) and learners’ lexical and syntactic complexity development (as the dependent variable) in this study. It is a non-parametric correlation coefficient test that was used in this study as the normality and randomness assumptions of data were not met (Bastick & Matalon, 2007).
To examine the frequency and range of these L2 chunks in detail, we take advantage of AntConc and Sketch Engine software built-in features, namely Concordancer and Normalised Frequency Data. The concordancer allows us to look at words in context, i.e., these words are technically known as concordances (see the qualitative analysis section 3.2 below). Both of the chosen software is used alternatively for the analysis part of this study. These tools are helpful for the task of the production of normalized frequency data (i.e., a word frequency list) which lists all words appearing in a corpus and specify how many times each one occurs in that corpus (see the quantitative analysis part 3.1 below). Concordances and frequency data exemplify respectively the two forms of analysis, namely qualitative and quantitative, that are equally important to corpus linguistics studies. The frequency data analysis in this study is useful to quantify the frequency and range of L2 chunks, which serves the quantitative part of this study. However, the concordances analysis of data examines in more detail these frequencies and range of L2 chunks, which serves the purpose of the qualitative part of the current study. Also, we used other tools for the calculation of the lexical and grammatical complexity such as Type-Toke Ratio (TTR) Calculator for the analysis of lexical complexity and ‘Web-based L2 Syntactic Complexity Analyzer’ (Ai & Lu, 2010) to obtain the number of AS-units for the analysis of the grammatical complexity. For the statistical part, SPSS version 21.0 was mainly used for running the required statistical tests and analyses in this research work.
We could build only a small linguistic corpus compared to existing corpora, but it is all new (number of unique words n =13,457 and number of tokens n = 15,551). The data in this corpus comprises students’ answers (which were elicited from written and oral samples) to a number of writing and speaking communicative tasks. The number of sentences produced by learners without any disfluency features (i.e., pauses, false starts, repetitions) was tallied and compared between the baseline and end-line data sets in the analyses of this study.
- Results
3.1 Quantitative Analysis
Analysis of Research Question 1: Frequency and Range of Acquired L2 Chunks
The first research question addressed the frequency and range of the acquired L2 chunks in learners’ oral and written production.
For the acquisition of the frequency values in this study, we use the normalised frequency (or relative frequency), which answers the question ‘How often might we assume we will see the word (i.e., in this study L2 chunk) per x words of running text?‘ Normalised frequencies are usually given per thousand words or per million words. Due to the limited amount of data in this study, we checked this parameter per thousand words. However, the range values of the L2 chunks were obtained manually by carefully examining the available data.
The following contingency Tables 1 and 2 demonstrate the frequency and range of correctly used L2 chunks in speech and writing samples after their exposure to YouTube captioned videos over five months.
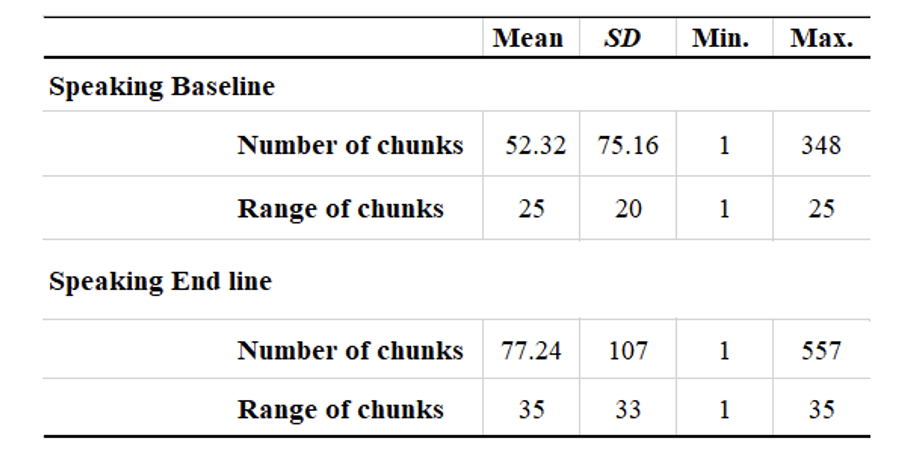
Table 1. Frequency and Range of Correctly Used Chunks in Learners’ L2 Speech.
Significance Test:
A chi-square test was used to check whether there was a significant difference in the frequency and the range of the chunks between the baseline and end line of learners’ L2 speech performance samples. The results (Table 1) revealed a significant change over time chi-square = 8.03, p <.05 for frequency, and chi-square = 2.85, p < .05 for range.
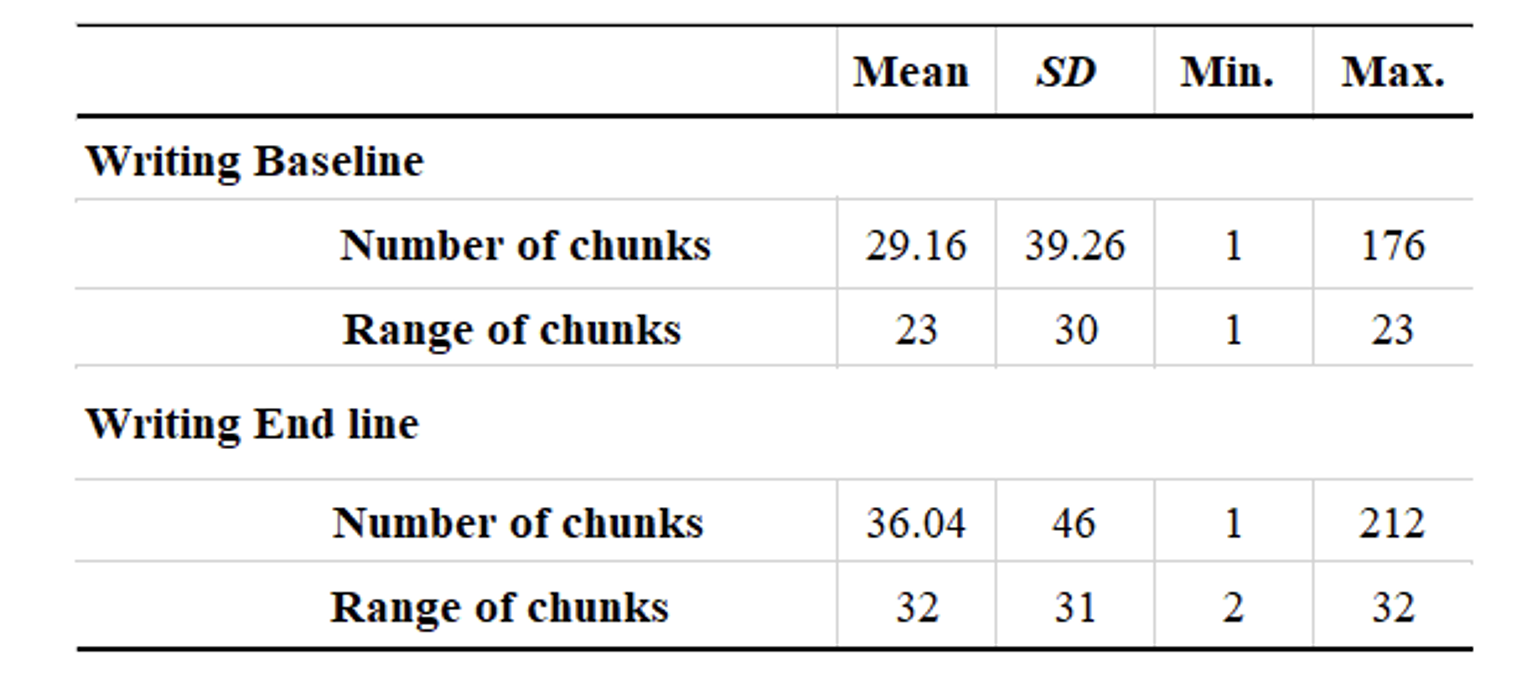
Table 2. Frequency and Range of Correctly Used Chunks in Learners’ L2 Writing.
Significance Test:
A chi-square test was used to check whether there was a significant difference in the frequency and the range of the chunks between the baseline and end line of learners’ L2 writing. The results (Table 2) revealed a significant change over time chi-square = 1.31, p <.05 for frequency, and chi-square = 2.53, p < .05 for range.
The answers to the first research question about the frequency and range of L2 chunks (which seem to have developed to some extent post the intervention as shown by the results above in Tables 1 & 2) were necessary to calculate the L2 complexity in relation to the acquired L2 chunks (Tables 3, 4, 5, 6). The following section displays this relation in more detail.
Frequency and Range of Acquired L2 Chunks in Relation to the Development of Complexity
This section addressed the development of grammatical and lexical complexity in both learners’ oral and writing production in relation to only the frequency of the acquired L2 chunks (see Tables 3, 4, 5, 6) and in relation to both frequency and range of the acquired L2 chunks (see Tables 7 & 8).
Grammatical Complexity
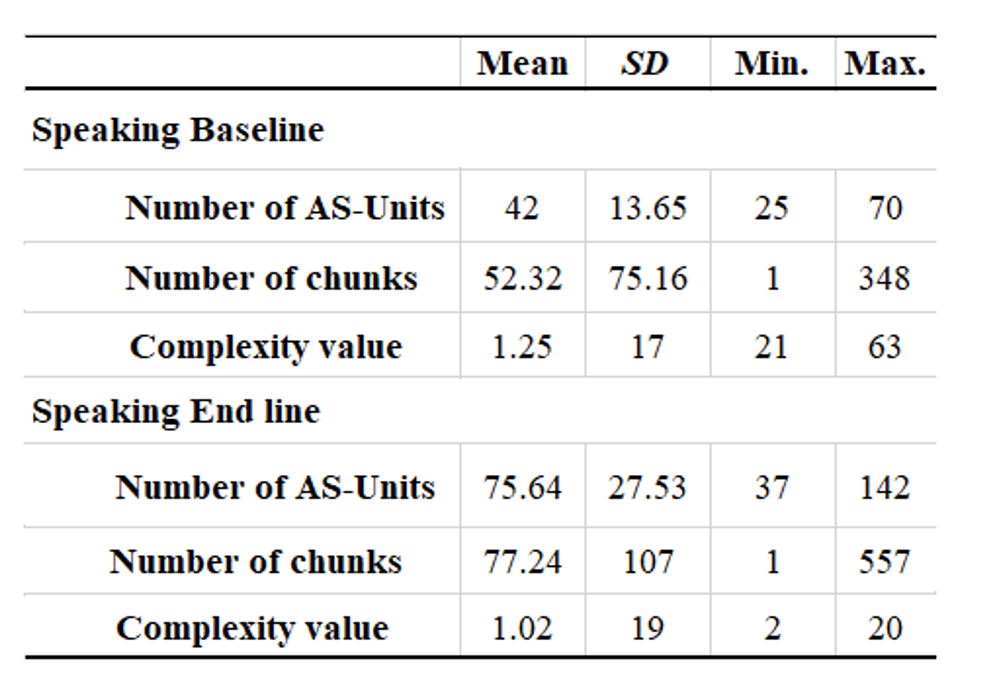
Grammatical complexity of speech was obtained by dividing the total number of L2 chunks by the total number of AS-Units in each of the baseline and end line of speech data. The descriptive statistics of the grammatical complexity values are displayed in Table 3 below. The baseline data revealed a total of 42 AS-Units from 14 learners compared to end line data which revealed a total of 75.64. Also, there seems to be an obvious increase in the average number of chunks that appeared in individual AS-Units —52.32 chunks per AS-Unit in the baseline data (SD = 75.16), and 77.24 chunks per AS-Unit in the end line data (SD = 107). However, a matched-pair t-test was used to examine the gain between the baseline and end line of learners’ grammatical complexity values in L2 speech. This test unfolded that the difference was not statistically significant, t = 1, df = 13, p = 0.5. The effect size, Cohen’s d of 0.01, also shows a small effect, indicating that the grammatical complexity value of speech in relation to the frequency of acquired L2 chunks did not increase over time.
Table 3. Grammatical Complexity of Learners’ L2 Speech.
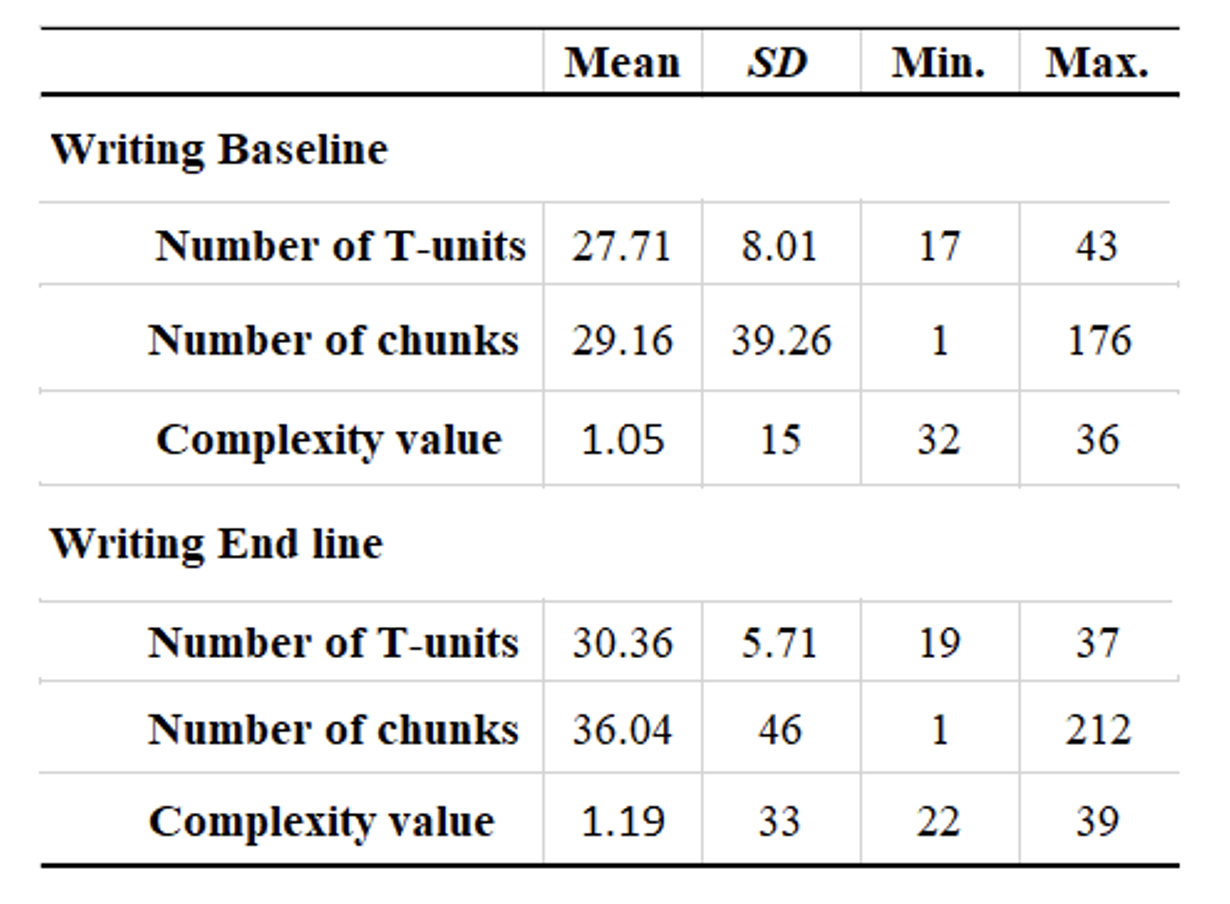
Grammatical complexity of writing was obtained by dividing the total number of chunks by the total number of T. units in each of the baseline and end line of writing data. The descriptive statistics of the grammatical complexity values are displayed in Table 4 below. The baseline data revealed a total of 27.71 T. units from 14 learners compared to end line data which revealed a total of 30.36. Also, there seems to be an obvious increase in the average number of chunks that appeared in individual T. units —29.16 chunks per T. unit in the baseline data (SD = 39.26), and 36.04 chunks per T. unit in the end line data (SD = 46). However, a matched-pair t-test demonstrated that the difference was not statistically significant, t = -1, df = 13, p = 0.5. The effect size, Cohen’s d of -0.005, also shows a small effect, indicating that the grammatical complexity value of writing in relation to the frequency of acquired L2 chunks did not increase over time.
Table 4. Grammatical Complexity of Learners’ L2 writing.
Lexical Complexity
Previous studies used type/token ratio formula (number of types/number of tokens) * 100 to obtain the lexical complexity (also known as vocabulary variation) within a written text or a person’s speech (Verspoor et al., 2008). In this connection, to get an idea of what percentage the acquired chunks constitute of this variation in both speech and writing data, we divided the number of chunks by the type/token ratio of the learners’ L2 speech (Table 5) and writing (Tables 6).
The descriptive statistics of the lexical complexity value of speech is displayed in Table 5 below. The baseline data revealed a total of 10 as the TTR value from 14 learners compared to end-line data which revealed a total of 9.5. However, there seems to be an obvious increase in the average number of chunks that appeared in individual AS-Units —52.32 chunks per AS-Unit in the baseline data (SD = 75.16), and 77.24 chunks per AS-Unit in the end-line data (SD = 107). Nonetheless, a matched-pair t-test unfolded that the difference was not significant, t = -1, df = 13, p = 0.5. The effect size, Cohen’s d of -0.001, also shows a small effect, indicating that the lexical complexity of speech value in relation to the frequency of acquired L2 chunks did not increase over time.
Table 5. Lexical Complexity of Learners’ L2 Speech.
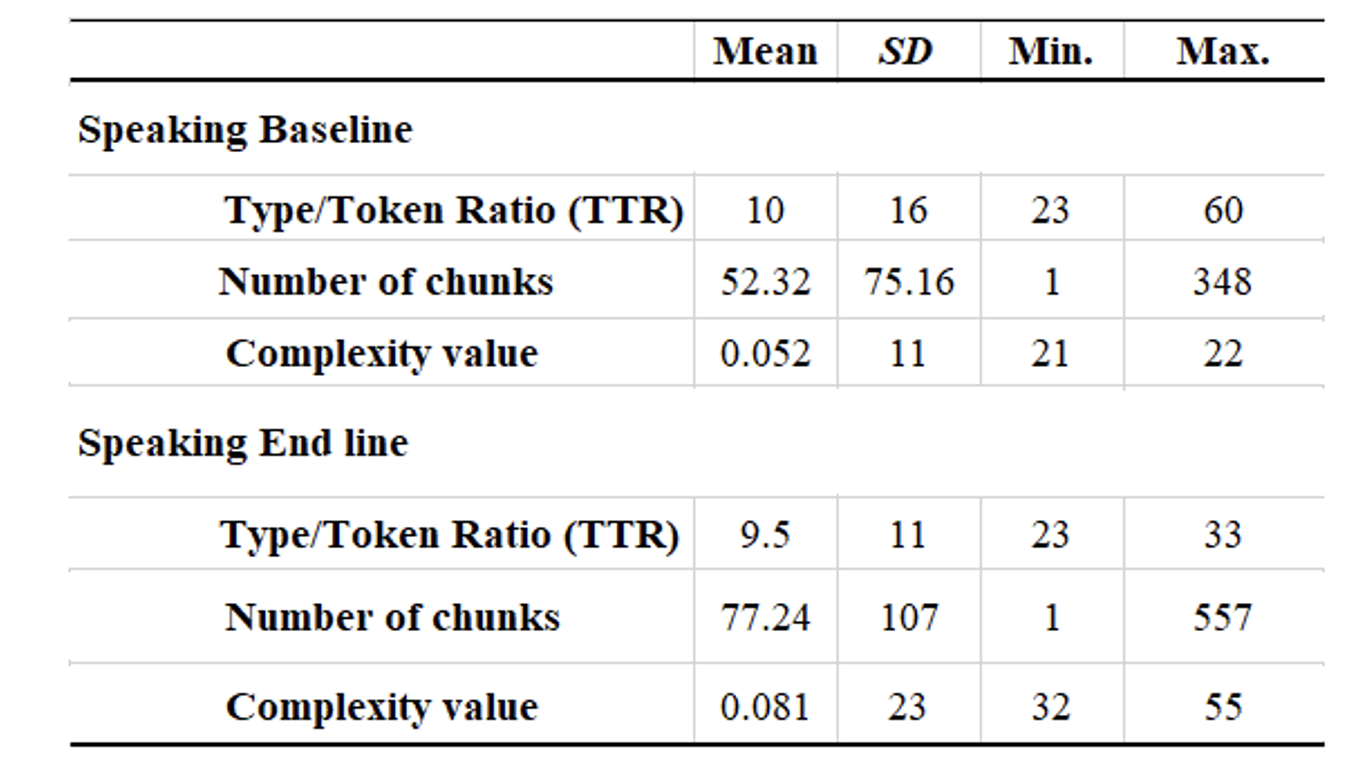
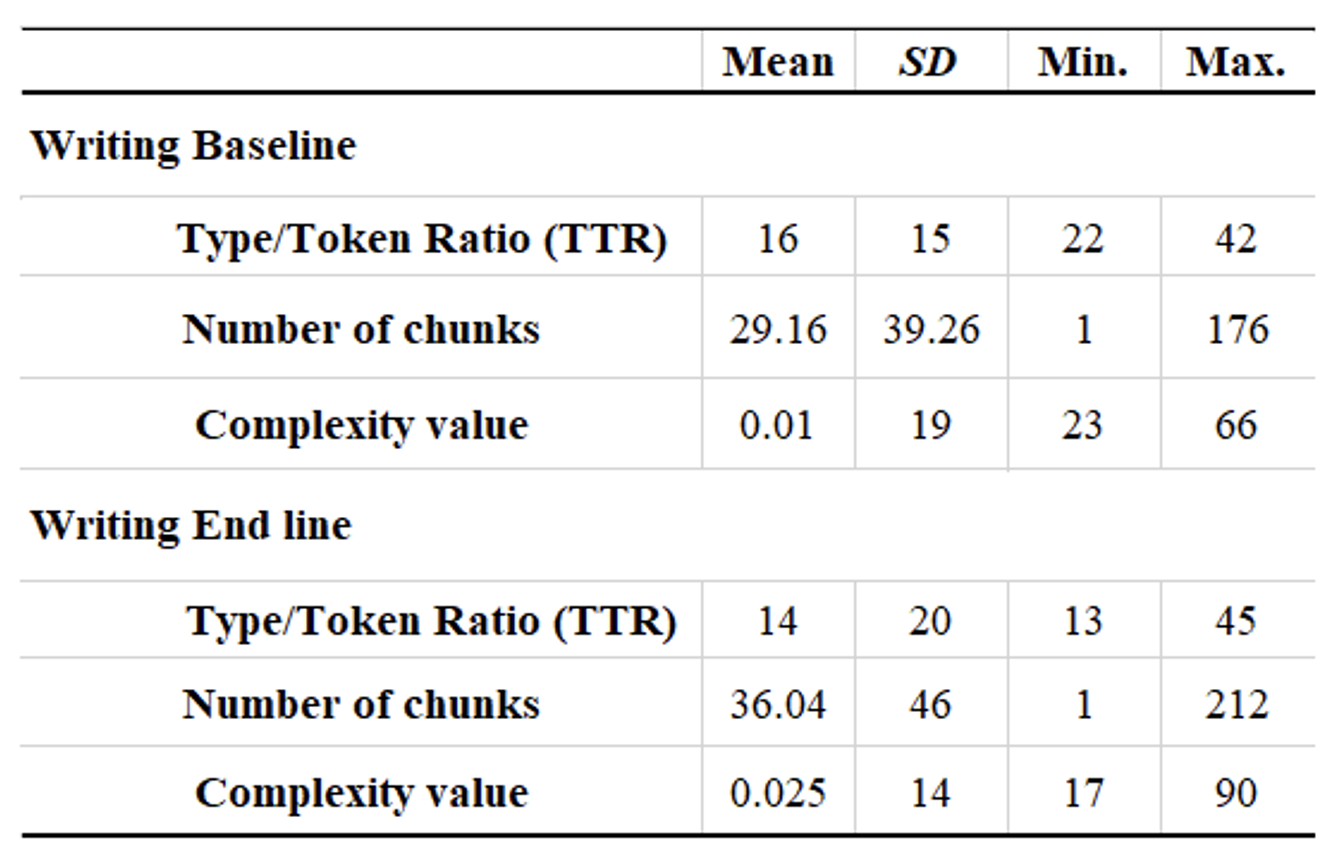
The descriptive statistics of the lexical complexity value of writing are displayed in Table 6 below. The baseline data revealed a total of 16 as the TTR value from 14 learners compared to end-line data which revealed a total of 14. However, there seems to be an obvious increase in the average number of chunks that appeared in individual T. units —29.16 chunks per T. unit in the baseline data (SD = 39.26), and 36.04 chunks per T. unit in the end-line data (SD = 46). Despite this, a matched-pair t-test unfolded that the difference was not statistically significant, t = -1, df = 13, p = 0.5. The effect size, Cohen’s d of -0.001, also shows a small effect, indicating that the lexical complexity of writing value in relation the frequency of acquired L2 chunks did not increase over time.
Table 6. Lexical Complexity of Learners’ L2 Writing.
Having determined both the grammatical and lexical complexity development values of learners’ writing and speech (which seem to have developed to some extent, though this development was not statistically significant, Tables 3, 4, 5, 6) in relation to the frequency and range values of L2 chunks (which seem to have developed, statistically speaking, Tables 1 & 2) post the five-month exposure period to the multimedia of YouTube captioned videos, we could further analyze the correlation between these values (see the correlation analysis and results next).
Analysis of Research Question 2: Correlation Results
Spearman’s correlation is employed to help explain if there is any established correlation between the frequency and range of the acquired L2 chunks (as the independent variables) and the development of learners’ lexical and syntactic complexity post-intervention (as the dependent variables) in this study.
Table 7. Correlation of Acquired Chunks and Complexity Development of Learners’ L2 Speech.
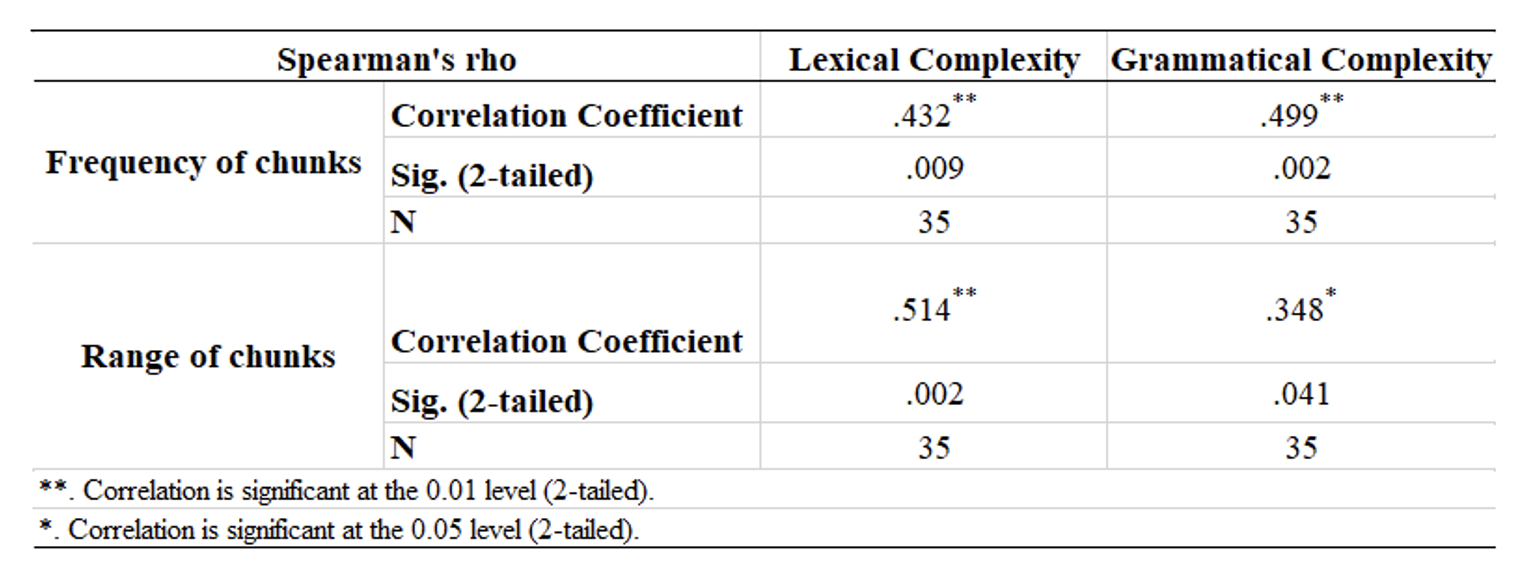
Findings in Table 7 demonstrate some positive correlation between both the frequency and range of chunks and the complexity development of learners’ L2 speech. Although significant results (realized in the given p values) were obtained, the observed correlation coefficients range from weak to moderate-sized only.
Table 8. Correlation of Acquired Chunks and Complexity Development of Learners’ L2 Writing.
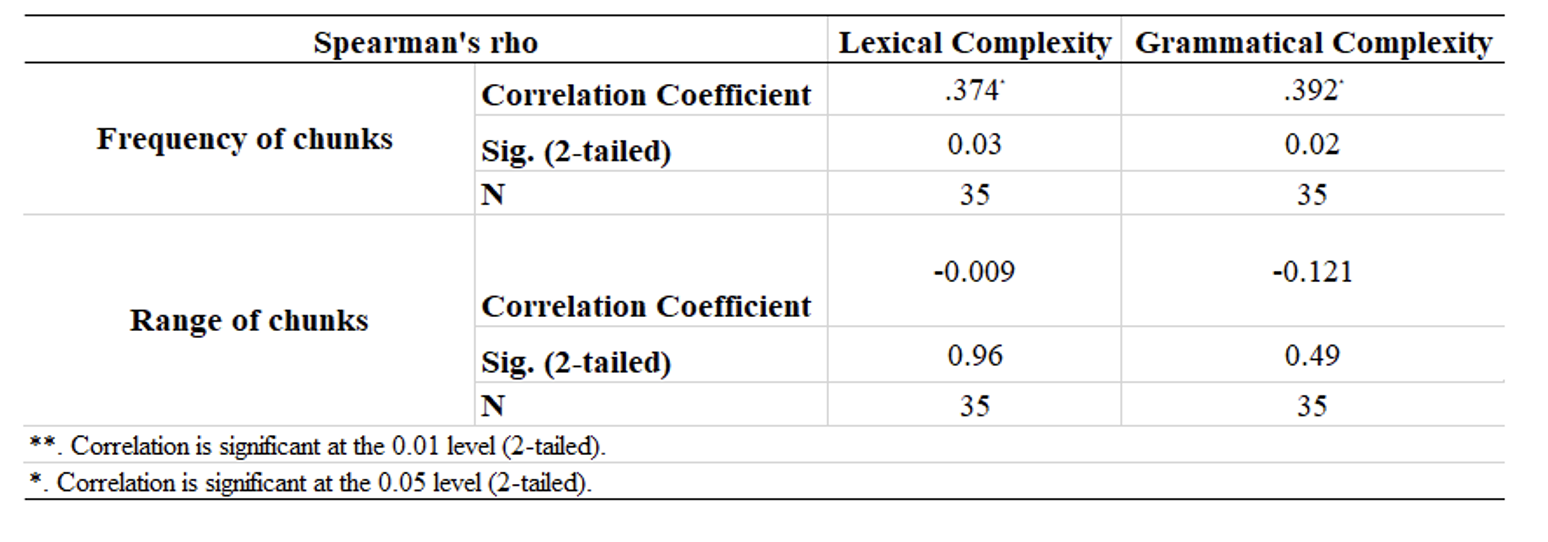
Similarly, findings in Table 8 demonstrate some positive correlation between the frequency of chunks and the complexity development of learners’ L2 writing. Although some significant results (realized in the given the p values) were obtained, the observed correlation coefficients are only weak-sized. Nevertheless, there is no correlation between the range of chunks and the complexity development of learners’ L2 writing.
3.2 Qualitative Analysis
As mentioned above, this study explores what is known as concordances since they are typically used to qualitatively analyze a body of sample language (i.e., corpus) to determine common usage. More specifically, we do concordance here to find out the common collocation of a word with other words (what basically constitutes a language chunk) as well as the frequency of collocation of two or more words. Table 9 displays some examples of the concordances in relation to L2 acquired chunks by learners, which were identified in the current corpus, followed by a discussion on this qualitative analysis of such concordances and some analytical examples from the corpus (figures 1 & 2) (see discussion section 4 below for more information).
Table 9. Lexico-Grammatical Chunks Identified and Analyzed in this Corpus-Based Study.
| Lexico-Grammatical Chunks | Examples | Frequency |
| ‘To be’ verb + going to + v
|
I’m going to travel to India… | 5 |
|
N + v + that clause
|
I think/ believe that…
|
34 |
| The adv + adj
|
The most important…
|
28 |
| Aux + adv + v
|
…may just call at… | 6 |
| V+ negation + adv + v | Don’t even think that…
|
7 |
|
If-clause and the main clause
|
If you have time, do me this favour…. |
36 |
| V clause + what /why/ how to + v | Teach them how to eat/ talk politely… | 4 |
| N+ aux + v + that clause | I can tell you that it’s nice… | 92 |
Significance test
When looking for a word’s collocations, we typically test the significance of the co-occurrence frequency of that word and everything that appears near it once or more in the corpus (Dévière, 2009; Gries, 2021).
Based on this corpus, we could see a number of different lexico-grammatical chunks of various structures seen in Table 9. The most frequent of these chunks (n. 92) was the ‘N+ aux+v+that clause’ chunk type as in I can tell you that it’s nice. The second most frequent (n. 36) is ‘If- clause and the main clause’ as in If you have time, do me this favour. The third most frequent chunks were the ‘N+ v +that clause’ (n. 34) as in I think/ believe that. The fourth most frequent chunks were ‘The adv + adj’ chunks (n. 28) as in the most important. The fifth most frequent chunks were ‘v+ negation + adv+ v’ chunks (n. 7) as in don’t even think that. The sixth most frequent chunks were ‘aux + adv +v’ chunks (n. 6) as in you may just call at this number. The seventh most frequent chunks were ‘to be+v+going to+ v’ chunks (n. 5) as in I’m going to travel to India. The eight most frequent chunks were ‘V clause + how to +v’ chunks (n. 4) as in teach them how to eat/ talk politely.
In Figures 1 and 2 below, we can see examples of Key Word In Context (KWIC) highlighted. In these examples, the concordances of ‘that’ and ‘going’ along with surrounding words in context are identified. In particular, the words that most commonly appear near the target words (their ‘common collocates’) as used by learners are highlighted. For instance, the ‘that’ and ‘going’ chunks occur in many locations of the sentence with different syntactic functions/ roles (see the discussion section below for more analysis on these two figures).
The following Figures 1 and 2 show two examples of the chunks as used in different contexts taken from the corpus in this study.
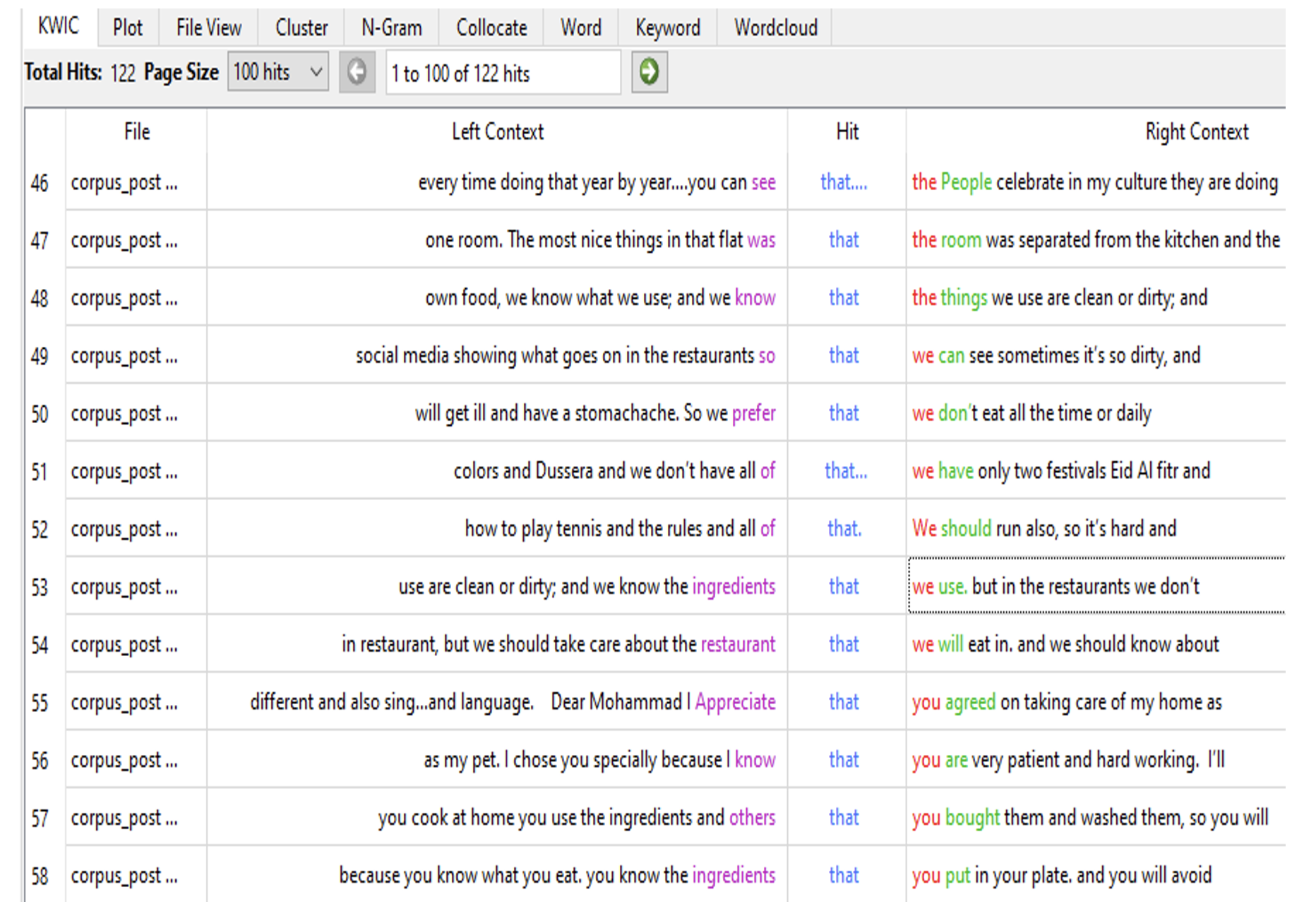
Figure 1. Concordance of “that” in Learners’ L2 Speech and Writing Task-Based Corpus.
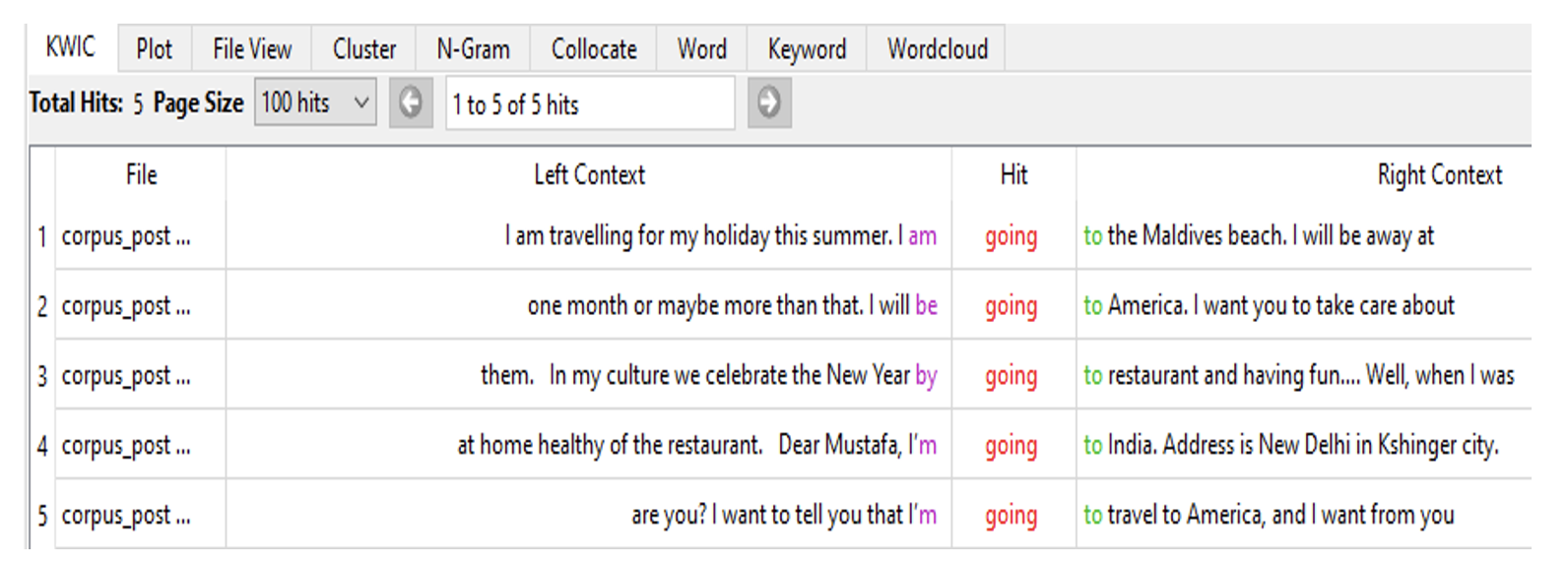
Figure 2. Concordance of “going” in Learners’ L2 Speech and Writing Task-Based Corpus.
- Discussion
This small-scale, corpus-based study explored two major issues. First, we examined learners’ L2 development of lexical and grammatical complexity in their L2 speech and writing from the perspective of the frequency and range of the acquired L2 chunks, depending on the linguistic corpus-driven insights. These Arabic-speaking ESL learners were frequently exposed to one ICT multimedia learning tool, namely YouTube captioned videos over the time span of five months and thus potentially acquired a large number of L2 chunks during their ESL learning process. This resulted in some fluency and accuracy progress of their L2 writing and speech performance. Second, we explored the correlation between the frequency and range of acquired L2 chunks by learners and their lexical and syntactic complexity development. Upon building the corpus of the writing and speech samples collected both before and after the intervention over five months, the development of lexical and grammatical complexity in L2 writing and speaking was analyzed from the perspective of the acquired L2 chunks, basically in terms of the frequency and range of the acquired L2 chunks. Based on the findings (Tables 1 & 2) in this study, the learners seem to have gained and thus produced a fairly good amount of chunks over time in terms of both the number and range of chunks demonstrated in both writing and speaking, indicating the increase in their writing and oral productivity over a short period of time.
This analytical corpus-based study of correctly used L2 chunks helped identify their frequency or number of occurrences and range in the learners’ L2 speech and writing communicative tasks (Tables 1 & 2). This finding indicated that a significant difference exists between the baseline and end-line data in this study. This suggested a notable gain in both the frequency and range of L2 chunks resulting from frequent exposure and engagement with online multimedia learning materials over time, in this case YouTube captioned videos. As seen in Tables 1 and 2, the frequency and range of L2 chunks produced per AS-Unit and T-unit obviously increased over a short time span. Moreover, the increasing level of grammatical and lexical complexity in learners’ individual utterances was evident in a variety of lexico-grammatical chunks that the learners used to construct utterances/ sentences in their L2 speech and writing. The notable increase in overall L2 oral and writing productivity may tell us that the learners accumulated a larger stock of grammatical chunks and phrase expressions, and used them to expand their utterances/ sentences in speech and writing.
Learners frequently used a wide range of lexico-grammatical chunks which seem to have expanded their communicative oral and written responses in real, new communicative tasks given to them. Some of the acquired chucks which appeared in this corpus included as well as, I appreciate it, twice a day/ week, a day, there’s nothing to worry about, as well, even if, again and again, but that doesn’t mean, but anyway, to name but a few. Furthermore, among these language chunks were some of the cohesive devices like ’for example’, ’and’, ’but’, ’therefore’, ’first of all’, ’in conclusion’, ’however’, ’moreover’. It’s worth noting here that these learners used individual chunks creatively and purposefully, by adding them together and fitting (i.e., by way of embedding) them within larger clausal units. As suggested by Taguchi (2008), learners use a set of memorized, individual chunks effectively as a means to create meaning and sustain a conversation for a long period of time in a task situation that they had never practiced in class.
A number of post hoc correlational analyses were conducted to gain some insights on the strength of association between the frequency and range of acquired L2 chunks (as the independent variable) (Tables 1 & 2) in relation to the development of L2 complexity (as the dependent variable) (Tables 3, 4, 5, 6). Correlation coefficients indicated some weak-to-moderate, positive correlations between variables in this study (Tables 7 & 8), suggesting that as the frequency and range of L2 chunks increase so does (to some extent) the L2 lexical and grammatical complexity in learners’ L2 speech and writing. These correlations were statistically significant, mainly in the learners’ L2 speech.
This can probably indicate that the greater number and range of the chunks that the learners accumulated over time seemed to have contributed to the development of L2 lexical and grammatical complexity of L2 speech and writing.
The above results seem to support the qualitative analysis findings in this study. Qualitative analysis findings in this study revealed different patterns of complexity development in relation to L2 chunks. One clear example that can be discussed here is the ‘that’ chunk which appeared in a variety of formats, mostly in an affirmative sentence describing things and people these learners are familiar with, and other times in a negative sentence for contradiction or denial of something or some information. The right-hand context in Figure 1 above illustrates the frequent occurrence of “that clause = that (as subordinator) + subject + verb (+ rest of clause)” construction (see line no. in 56 the Figure 1). Also, the left-hand context in Figure 1 shows a variety of structures that would frequently occur with “that construction” such as: the ‘to be’ verbs, where ‘that clause’ serves the function of a subject complement (see line no. 47 in Figure 1); following a noun, where ‘that clause’ serves the function of a noun complement (see line no. 53 in Figure 1); following a main verb, where ‘that clause’ serves the function of a direct object (see line no. 46 in Figure 1); so + that as a conjunction which serves to introduce clauses of reason and explanation (see line no. 49 in Figure 1).
Another chunk construction that followed a simple sentence structure and contained only a few additional constructions is “going”. The right-hand context in Figure 2 above illustrates the frequent occurrence of “going = going (v + ing) + to + verb/ destination + rest of clause” construction (see line no. 1 in Figure 2). Also, the left-hand context in Figure 2 shows a variety of structures that would frequently occur with “going construction” such as: “to be” v.+ going (see line no. 4 in Figure 2); aux + be + going (see line no. 2 in Figure 2); preposition + going (gerund form) + rest of the clause, where “going” serves as the object of preposition (see line no. 3 in Figure 2).
These findings suggest a potential relationship between the frequency and range of L2 chunks and complexity in learners’ speech and writing production. As we could see that learners in this study could improve greatly in terms of chunk number or frequency, chunk size or range; this could have been “on the basis of consolidation of chunks and vocabulary upon which the chunks were built” (Taguchi, 2008).
In many instances in this corpus-based study, we could see that learners used individual L2 chunks creatively and purposefully in both writing and speech, by adding them together and embedding them within larger clausal units. This suggests some interaction (or internal mechanism followed by L2 learners) between chunk learning and rule-based learning, wherein the learners analyze the chunks by constituents and use them in a productive manner by combining them with other patterns. To learners, this may seem a faster and easier way, i.e., shortcut to express and produce both utterances/ sentences in task situations that they had never been before.
It should be mentioned that these chunks were used frequently in these videos. Individual component chunks introduced in these videos were (in many cases) retained and used as extensions toward more complex, longer utterances/ sentences. In fact, learners were encouraged to identify and record chunks (e.g., lexical and grammatical) when they find them in these videos. Afterward, learners were constantly encouraged to try to make use of the new target language input (i.e., chunks) in the speaking/ writing tasks given to them (Alobaid, 2020; 2022).
These findings confirm previous studies (Alobaid, 2020; 2022a) and also lend support to predominant claims (although not yet adequately attested) in the literature that learners’ linguistic systems develop by building up larger units from small modular components. Longer and more complex utterances are constructed by using modular elements as building blocks, and chunks are integrated into a larger discourse structure by juxtaposition and embedding (Ellis, 1996, 2003; Taguchi, 2008).
- Limitations and Implications of Study
The sample size of input data in our corpus is a limitation. Building larger corpora would have obviously yielded more informative and robust results. Therefore, the results of this research should be treated with some caution, although they seem to be, by and large, statistically significant.
This corpus-based study is in favor of Sinclair’ (1991) study who, based on his experience with concordances with the COBUILD project, emphasizes the role of formulaic expressions (multiword units), which he terms ‘idiom principle’, in communication and sees them as motivated by economy of effort. This motivation may probably make these chunks appealing for many L2 learners.
This study clearly supports that bilingual learners of a language like English may still need intensified and attentive learning and awareness of chunks for more complex L2 lexis and grammar and ultimately more fluent and accurate usage of that language.
The availability of simple and easy (especially for low-level learners) to grasp L2 chunks in the leaners’ target language learning environment is recommended, since this may help learners acquiring and integrating those chunks into their spontaneous L2 output. This work suggests that ICT-based language learning such as captioned videos can be one way to make learning such chunks more easily possible.
References
Ai, H., & Lu, X. (2010). A web-based system for automatic measurement of lexical complexity. In 27th Annual Symposium of the Computer-Assisted Language Consortium (CALICO-10). Amherst, MA. June (pp. 8-12).
Alobaid, A. (2020). Smart multimedia learning of ICT: role and impact on language learners’ writing fluency— YouTube online English learning resources as an example. Smart Learn. Environ. 7, 24.
Alobaid, A. (2021). ICT multimedia learning affordances: role and impact on ESL learners’ writing accuracy development. Heliyon, 7(7), e07517.
Alobaid A. (2022a) ICT Virtual Multimedia Learning Tools/Affordances: The Case of Narrow Listening to YouTube Multimedia-Based Comprehensible Input for the Development of ESL Learners’ Oral Fluency. In: Hamdan A., Hassanien A.E., Mescon T., Alareeni B. (eds) Technologies, Artificial Intelligence and the Future of Learning Post-COVID-19. Studies in Computational Intelligence, vol 1019. Springer, Cham.
Alobaid, A. (2022b). ICT Virtual Multimedia Learning Tools/Environments: Role and Impact on ESL Learners’ Development of Speech Accuracy—YouTube as an Example. In Digital Communication and Learning (pp. 143-182). Springer, Singapore.
Anisimov, I., Makarova, E., & Polyakov, V. (2018). Chunking in Dependency Model and Spelling Correction in Russian and English. In Proceedings of SAI Intelligent Systems Conference (IntelliSys) 2016: Volume 1 (pp. 218-231). Springer International Publishing.
Bastick, T., & Matalon, B. (2007). Research: New and practical approaches. Chalkboard Press. Business Education, 82(5), 282-29.
Bulté, B., & Housen, A. (2012). Defining and operationalising L2 complexity. Dimensions of L2 Performance and Proficiency: Complexity, Accuracy and Fluency in SLA, 32, 21.
Conklin, K., & Schmitt, N. (2008). Formulaic sequences: Are they processed more quickly than nonformulaic language by native and nonnative speakers?. Applied Linguistics, 29(1), 72-89.
Dévière, E. (2009). Analyzing linguistic data: a practical introduction to statistics using R.
Ellis, N. (1996). Sequencing in SLA: Phonological memory, chunking, and points of order. Studies in Second Language Acquisition, 18, 91-126.
Ellis, N. (2003). Constructions, Chunking, and Connectionism: The emergence of second language structure. In C. Doughty & M. Long (Eds.), Handbook of SLA (pp. 63-103). Malden, MA: Blackwell.
Foster, P., Tonkyn, A., & Wigglesworth, G. (2000). Measuring spoken language: A unit for all reasons. Applied linguistics, 21(3), 354-375.
Gries, S. T. (2021). Statistics for Linguistics with R. In Statistics for Linguistics with R. De Gruyter Mouton.
Hunt, K. W. (1966). Recent measures in syntactic development. Elementary English, 43(7), 732-739.
Hunston, S. (2010). How can a corpus be used to explore patterns?. In The Routledge handbook of corpus linguistics (pp. 140-154). Routledge.
Lewis, M. (1993). The lexical approach (Vol. 1, p. 993). Hove: Language teaching publications.
Lewis, M., Gough, C., Martínez, R., Powell, M., Marks, J., Woolard, G. C., & Ribisch, K. H. (1997). Implementing the lexical approach: Putting theory into practice (Vol. 3, No. 1, pp. 223-232). Hove: Language Teaching Publications.
Lintunen, P., & Mäkilä, M. (2014). Measuring syntactic complexity in spoken and written learner language: Comparing the incomparable?. Research in Language, 12(4), 377-399.
McCarthy, M., & Carter, R. (2004). This that and the other: Multi-word clusters in spoken English as visible patterns of interaction. TEANGA, the Journal of the Irish Association for Applied Linguistics, 21, 30-52.
Nassaji, H. (2003). L2 vocabulary learning from context: Strategies, knowledge sources, and their relationship with success in L2 lexical inferencing. Tesol Quarterly, 37(4), 645-670.
Nattinger, J., & DeCarrico, J. (1992). Lexical phrases and language teaching. Oxford:
Oxford University Press.
Norris, J. M., & Ortega, L. (2009). Towards an organic approach to investigating CAF in instructed SLA: The case of complexity. Applied linguistics, 30(4), 555-578.
Pawley, A., & Syder, H. (2000). The one-clause-at-a-time hypothesis. In H. Riggenbach (Ed.), Perspectives on fluency (pp. 163-199). Ann Arbor: University of Michigan Press.
Poole, R. (2018). A guide to using corpora for English language learners. Edinburgh University Press.
Saito, K., & Hanzawa, K. (2018). The role of input in second language oral ability development in foreign language classrooms: A longitudinal study. Language Teaching Research, 22(4), 398-417.
Sinclair, J. (1991). Genre analysis: English in academic and research settings. Cambridge: Cambridge University Press.
Skehan, P. (1998). A cognitive approach to language learning. Oxford: Oxford University Press.
Taguchi, N. (2008). Building language blocks in L2 Japanese: Chunk learning and the development of complexity and fluency in spoken production. Foreign Language Annals, 41(1), 132-156.
Vanderplank, R. (1988). The value of teletext sub-titles in language learning. ELT journal, 42(4), 272-281.
Vanderplank, R. (1990). Paying attention to the words: Practical and theoretical problems in watching television programmes with uni-lingual (CEEFAX) sub-titles. System, 18(2), 221-234.
Verspoor, M., Lowie, W., & Van Dijk, M. (2008). Variability in second language development from a dynamic systems perspective. The Modern Language Journal, 92(2), 214-231.
Winke, P., Gass, S., & Sydorenko, T. (2010). The effects of captioning videos used for foreign language listening activities. Michigan State University. Language Learning & Technology, 14(1), 65-86.
Winke, P., Gass, S., & Sydorenko, T. (2013). Factors influencing the use of captions by foreign language learners: An eye‐tracking study. The Modern language journal, 97(1), 254-275.
Wray, A. (2008). Formulaic language: Pushing the boundaries. Oxford University Press.
Yang, P. (2020). The Cognitive and Psychological Effects of YouTube Video Captions and Subtitles on Higher-Level German Language Learners. In: Freiermuth M., Zarrinabadi N. (eds) Technology and the Psychology of Second Language Learners and Users. New Language Learning and Teaching Environments. Palgrave Macmillan, Cham.
